
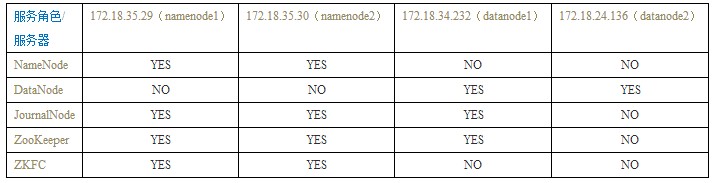
一、服务器分布及相关说明
1、服务器角色

1、JDK安装
- # tar xvzf jdk-7u45-linux-x64.tar.gz -C/usr/local
- # cd /usr/local
- # ln -s jdk1.7.0_45 jdk
- # vim /etc/profile
- export JAVA_HOME=/usr/local/jdk
- export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
- export PATH=$PATH:$JAVA_HOME/bin
- # source /etc/profile
- http://www.scala-lang.org/files/archive/scala-2.10.3.tgz
- # tar xvzf scala-2.10.3.tgz -C/usr/local
- # cd /usr/local
- # ln -s scala-2.10.3 scala
- # vim /etc/profile
- export SCALA_HOME=/usr/local/scala
- export PATH=$PATH:$SCALA_HOME/bin
- # source /etc/profile
- # vim /etc/hosts
- 172.18.35.29 namenode1
- 172.18.35.30 namenode2
- 172.18.34.232 datanode1
- 172.18.24.136 datanode2
1、ZooKeeper安装
- http://apache.dataguru.cn/zookeeper/stable/zookeeper-3.4.5.tar.gz
- # tar xvzf zookeeper-3.4.5.tar.gz -C/usr/local
- # cd /usr/local
- # ln -s zookeeper-3.4.5 zookeeper
- # vim /etc/profile
- export ZOO_HOME=/usr/local/zookeeper
- export ZOO_LOG_DIR=/data/hadoop/zookeeper/logs
- export PATH=$PATH:$ZOO_HOME/bin
- # source /etc/profile
- # mkdir -p/data/hadoop/zookeeper/{data,logs}
- # vim /usr/local/zookeeper/conf/zoo.cfg
- tickTime=2000
- initLimit=10
- syncLimit=5
- dataDir=/data/hadoop/zookeeper/data
- clientPort=2181
- server.1=172.18.35.29:2888:3888
- server.2=172.18.35.30:2888:3888
- server.3=172.18.34.232:2888:3888
- echo 1 > /data/hadoop/zookeeper/data/myid
- echo 2 > /data/hadoop/zookeeper/data/myid
- echo 3 > /data/hadoop/zookeeper/data/myid



1、hadoop环境安装
- # tar xvzf hadoop-2.2.0.tgz -C/usr/local
- # cd /usr/local
- # ln -s hadoop-2.2.0 hadoop
- # vim /etc/profile
- export HADOOP_HOME=/usr/local/hadoop
- export HADOOP_PID_DIR=/data/hadoop/pids
- export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
- export HADOOP_OPTS="$HADOOP_OPTS-Djava.library.path=$HADOOP_HOME/lib/native"
- export HADOOP_MAPRED_HOME=$HADOOP_HOME
- export HADOOP_COMMON_HOME=$HADOOP_HOME
- export HADOOP_HDFS_HOME=$HADOOP_HOME
- export YARN_HOME=$HADOOP_HOME
- export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
- export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- # mkdir -p /data/hadoop/{pids,storage}
- # mkdir -p/data/hadoop/storage/{hdfs,tmp,journal}
- # mkdir -p/data/hadoop/storage/tmp/nodemanager/{local,remote,logs}
- # mkdir -p/data/hadoop/storage/hdfs/{name,data}
- <?xml version="1.0" encoding="UTF-8"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://appcluster</value>
- </property>
- <property>
- <name>io.file.buffer.size</name>
- <value>131072</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/data/hadoop/storage/tmp</value>
- </property>
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>172.18.35.29:2181,172.18.35.30:2181,172.18.34.232:2181</value>
- </property>
- <property>
- <name>ha.zookeeper.session-timeout.ms</name>
- <value>2000</value>
- </property>
- <property>
- <name>fs.trash.interval</name>
- <value>4320</value>
- </property>
- <property>
- <name>hadoop.http.staticuser.use</name>
- <value>root</value>
- </property>
- <property>
- <name>hadoop.proxyuser.hadoop.hosts</name>
- <value>*</value>
- </property>
- <property>
- <name>hadoop.proxyuser.hadoop.groups</name>
- <value>*</value>
- </property>
- <property>
- <name>hadoop.native.lib</name>
- <value>true</value>
- </property>
- </configuration>
- <?xml version="1.0" encoding="UTF-8"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/data/hadoop/storage/hdfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/data/hadoop/storage/hdfs/data</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- <property>
- <name>dfs.blocksize</name>
- <value>67108864</value>
- </property>
- <property>
- <name>dfs.datanode.du.reserved</name>
- <value>53687091200</value>
- </property>
- <property>
- <name>dfs.webhdfs.enabled</name>
- <value>true</value>
- </property>
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- <property>
- <name>dfs.permissions.enabled</name>
- <value>false</value>
- </property>
- <property>
- <name>dfs.nameservices</name>
- <value>appcluster</value>
- </property>
- <property>
- <name>dfs.ha.namenodes.appcluster</name>
- <value>nn1,nn2</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.appcluster.nn1</name>
- <value>namenode1:8020</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.appcluster.nn2</name>
- <value>namenode2:8020</value>
- </property>
- <property>
- <name>dfs.namenode.servicerpc-address.appcluster.nn1</name>
- <value>namenode1:53310</value>
- </property>
- <property>
- <name>dfs.namenode.servicerpc-address.appcluster.nn2</name>
- <value>namenode2:53310</value>
- </property>
- <property>
- <name>dfs.namenode.http-address.appcluster.nn1</name>
- <value>namenode1:8080</value>
- </property>
- <property>
- <name>dfs.namenode.http-address.appcluster.nn2</name>
- <value>namenode2:8080</value>
- </property>
- <property>
- <name>dfs.datanode.http.address</name>
- <value>0.0.0.0:8080</value>
- </property>
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://namenode1:8485;namenode2:8485;datanode1:8485/appcluster</value>
- </property>
- <property>
- <name>dfs.client.failover.proxy.provider.appcluster</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>sshfence(root:36000)</value>
- </property>
- <property>
- <name>dfs.ha.fencing.ssh.private-key-files</name>
- <value>/root/.ssh/id_dsa_nn1</value>
- </property>
- <property>
- <name>dfs.ha.fencing.ssh.connect-timeout</name>
- <value>30000</value>
- </property>
- <property>
- <name>dfs.journalnode.edits.dir</name>
- <value>/data/hadoop/storage/hdfs/journal</value>
- </property>
- <property>
- <name>dfs.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
- <property>
- <name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
- <value>60000</value>
- </property>
- <property>
- <name>ipc.client.connect.timeout</name>
- <value>60000</value>
- </property>
- <property>
- <name>dfs.image.transfer.bandwidthPerSec</name>
- <value>41943040</value>
- </property>
- <property>
- <name>dfs.namenode.accesstime.precision</name>
- <value>3600000</value>
- </property>
- <property>
- <name>dfs.datanode.max.transfer.threads</name>
- <value>4096</value>
- </property>
- </configuration>
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>namenode1:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>namenode1:19888</value>
- </property>
- </configuration>
- <?xml version="1.0"?>
- <configuration>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- <property>
- <name>yarn.resourcemanager.scheduler.address</name>
- <value>namenode1:8030</value>
- </property>
- <property>
- <name>yarn.resourcemanager.resource-tracker.address</name>
- <value>namenode1:8031</value>
- </property>
- <property>
- <name>yarn.resourcemanager.address</name>
- <value>namenode1:8032</value>
- </property>
- <property>
- <name>yarn.resourcemanager.admin.address</name>
- <value>namenode1:8033</value>
- </property>
- <property>
- <name>yarn.nodemanager.address</name>
- <value>namenode1:8034</value>
- </property>
- <property>
- <name>yarn.nodemanager.webapp.address</name>
- <value>namenode1:80</value>
- </property>
- <property>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>namenode1:80</value>
- </property>
- <property>
- <name>yarn.nodemanager.local-dirs</name>
- <value>${hadoop.tmp.dir}/nodemanager/local</value>
- </property>
- <property>
- <name>yarn.nodemanager.remote-app-log-dir</name>
- <value>${hadoop.tmp.dir}/nodemanager/remote</value>
- </property>
- <property>
- <name>yarn.nodemanager.log-dirs</name>
- <value>${hadoop.tmp.dir}/nodemanager/logs</value>
- </property>
- <property>
- <name>yarn.nodemanager.log.retain-seconds</name>
- <value>604800</value>
- </property>
- <property>
- <name>yarn.nodemanager.resource.cpu-vcores</name>
- <value>16</value>
- </property>
- <property>
- <name>yarn.nodemanager.resource.memory-mb</name>
- <value>50320</value>
- </property>
- <property>
- <name>yarn.scheduler.minimum-allocation-mb</name>
- <value>256</value>
- </property>
- <property>
- <name>yarn.scheduler.maximum-allocation-mb</name>
- <value>40960</value>
- </property>
- <property>
- <name>yarn.scheduler.minimum-allocation-vcores</name>
- <value>1</value>
- </property>
- <property>
- <name>yarn.scheduler.maximum-allocation-vcores</name>
- <value>8</value>
- </property>
- </configuration>
- /usr/local/hadoop/etc/hadoop/hadoop-env.sh
- /usr/local/hadoop/etc/hadoop/mapred-env.sh
- /usr/local/hadoop/etc/hadoop/yarn-env.sh
- export JAVA_HOME=/usr/local/jdk
- export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
- export HADOOP_HOME=/usr/local/hadoop
- export HADOOP_PID_DIR=/data/hadoop/pids
- export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
- export HADOOP_OPTS="$HADOOP_OPTS-Djava.library.path=$HADOOP_HOME/lib/native"
- export HADOOP_PREFIX=$HADOOP_HOME
- export HADOOP_MAPRED_HOME=$HADOOP_HOME
- export HADOOP_COMMON_HOME=$HADOOP_HOME
- export HADOOP_HDFS_HOME=$HADOOP_HOME
- export YARN_HOME=$HADOOP_HOME
- export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
- export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
- export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- # vim /usr/local/hadoop/etc/hadoop/slaves
- datanode1
- datanode2













1、Spark安装与配置





相关推荐
Expert Hadoop Administration Managing Tuning and Securing Spark YARN and HDFS 英文无水印pdf pdf使用FoxitReader和PDF-XChangeViewer测试可以打开
1. 解压Spark安装包 2. 配置Hadoop生态组件相关环境变量 2. 在 master 节点上,关闭HDFS的安全模式: 3. 在 master 节点上
Spark on Yan集群搭建的详细过程,减少集群搭建的时间
【讲义-第10期Spark公益大讲堂】Spark on Yarn-.pdf
■ 计算框架在Hadoop 中的作用 ■ YARN 的设计目的和基本架构 ...■ Apache Spark 概念 ■ YARN 如何分配集群资源 ■ YARN 如何处理故障 ■ 如何查看和管理YARN 应用程序 ■ 如何访问YARN 应用程序日志
Spark on Yarn模式部署.docx
基于docker搭建spark on yarn及可视化桌面.doc
java提交spark任务到yarn平台的配置讲解共9页.pdf.zip
。。。
。。。
spark初始化源码阅读sparkonyarn的client和cluster区别
#资源达人分享计划#
基于SparkonYarn的淘宝数据挖掘平台
Yarn ResourceManager HA配置,Yarn ResourceManager HA配置
SPARK2_ON_YARN-2.4.0 jar包下载
本来不打算写的了,但是真的是闲来无事,整天看美剧也没啥意思。这一章打算讲一下Spark onyarn的实现,1.0.0里面...在第一章《spark-submit提交作业过程》的时候,我们讲过Sparkonyarn的在cluster模式下它的main clas
Spark On Yarn完全分布式集群环境搭建文档。 分为如下几部分: 1、环境的准备; 2、Zookeeper完全分布式搭建; 3、Hadoop2.0 HA集群搭建步骤介绍; 4、Spark On Yarn搭建介绍; 5、集群启动介绍; 最新最全的java培训视频...
三种方式的spark on kubernetes对比,第一种:spark原生支持Kubernetes资源调度;第二种:google集成的Kubernetes的spark插件sparkoperator;第三种:standalone方式运行spark集群
Ambari2.1.0安装配置(hadoop yarn spark集群安装配置)
前提:配置好执行脚本的主机到其他主机的ssh登录 脚本使用:vim编辑脚本,按照自己的配置修改主机号,我的是hadoop1、2是NN;hadoop2、3是Spark Master;hadoop3还是RM;hadoop4、5、6是DN、NM、Spark Worker。编辑...