
1:Spark的编译
Spark可以通过SBT(Scala Build Tool)或者Maven来编译,官方提供的二进制安装文件是用Maven编译,如果是要在YARN集群上运行的话,还需要再用SBT编译一下,生成YARN client端使用的jar包;最好是直接对源码使用SBT进行编译而生成YARN client端使用的jar包。笔者在测试过程中,对Maven编译过的Spark进行SBT二次编译后,在运行部分例子的时候有错误发生。
A:Maven编译
笔者使用的环境曾经编译过Hadoop2.2.0(参见hadoop2.2.0源码编译(CentOS6.4)),所以不敢确定Maven编译过程中,Spark是不是需要编译Hadoop2.2.0中使用的部分底层软件(看官方资料是需要Protobuf2.5)。除了网络下载不给力而不断的中止、然后重新编译而花费近1天的时间外,编译过程还是挺顺利的。
maven编译时,首先要进行设置Maven使用的内存项配置:
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
然后用Maven编译:
mvn -Pnew-yarn -Dhadoop.version=2.2.0 -Dyarn.version=2.2.0 -DskipTestspackage
参考文档:Building Spark with Maven
B:SBT编译
Spark源码和二进制安装包都绑定了SBT。值得注意的是,如果要使用Scala进行Spark应用开发,必须使用和Spark版本相对应版本的Scala,如:Spark0.8.1对应的Scala2.9.3。对于不匹配的Scala应用开发可能会不能正常工作。
SBT编译命令:
SPARK_HADOOP_VERSION=2.2.0 SPARK_YARN=true ./sbt/sbt assembly
二种编译都是在Spark根目录下运行。在SBT编译过程中如果网络不给力,手工中断编译(ctrl+z)后要用kill-9 将相应的进程杀死后,然后再重新编译,不然会被之前的sbt进程锁住而不能重新编译。
2:Spark运行
Spark可以单独运行,也可以在已有的集群上运行,如Amazon EC2、Apache Mesos、Hadoop YARN。下面用Spark自带的例程进行测试,运行的时候都是在Spark的根目录下进行。如果需要知道运行更详细的信息,可以使用log4j,只要在根目录下运行:
cp conf/log4j.properties.template conf/log4j.properties
A:本地运行
./run-example org.apache.spark.examples.SparkPi local
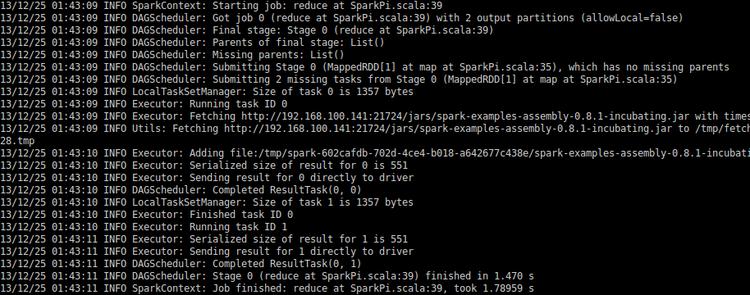
也可以多线程方式运行,下面的命令就是开4个线程。
./run-example org.apache.spark.examples.SparkPi local[4]
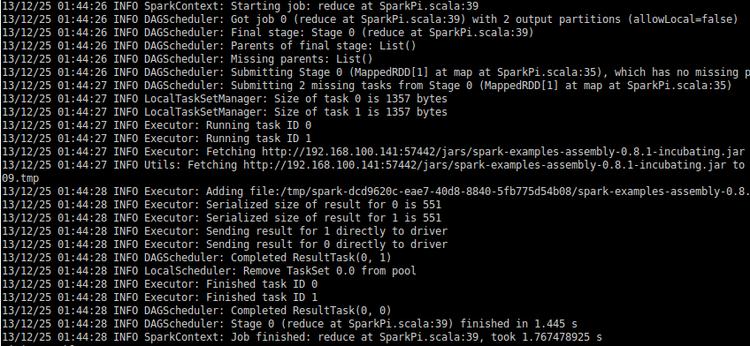
B:YARN集群
启动Hadoop2.2.0集群
确保环境变量HADOOP_CONF_DIR或YARN_CONF_DIR已经设置
在YARN集群中运行Spark应用程序的命令:
- SPARK_JAR=<SPARK_ASSEMBLY_JAR_FILE> ./spark-classorg.apache.spark.deploy.yarn.Client \
- --jar <YOUR_APP_JAR_FILE> \
- --class <APP_MAIN_CLASS> \
- --args <APP_MAIN_ARGUMENTS> \
- --num-workers <NUMBER_OF_WORKER_MACHINES> \
- --master-class <ApplicationMaster_CLASS>
- --master-memory <MEMORY_FOR_MASTER> \
- --worker-memory <MEMORY_PER_WORKER> \
- --worker-cores <CORES_PER_WORKER> \
- --name <application_name> \
- --queue <queue_name> \
- --addJars <any_local_files_used_in_SparkContext.addJar> \
- --files <files_for_distributed_cache> \
- --archives <archives_for_distributed_cache>
例1计算PI,可以看出程序运行时是先将运行文件上传到Hadoop集群的,所以客户端最好是和Hadoop集群在一个局域网里。
- SPARK_JAR=./assembly/target/scala-2.9.3/spark-assembly-0.8.1-incubating-hadoop2.2.0.jar \
- ./spark-class org.apache.spark.deploy.yarn.Client \
- --jar examples/target/scala-2.9.3/spark-examples-assembly-0.8.1-incubating.jar \
- --class org.apache.spark.examples.SparkPi \
- --args yarn-standalone \
- --num-workers 3 \
- --master-memory 2g \
- --worker-memory 2g \
- --worker-cores 1
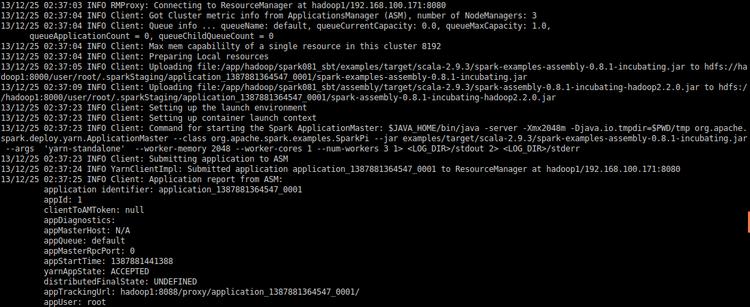
例2计算TC
- SPARK_JAR=./assembly/target/scala-2.9.3/spark-assembly-0.8.1-incubating-hadoop2.2.0.jar \
- ./spark-class org.apache.spark.deploy.yarn.Client \
- --jar examples/target/scala-2.9.3/spark-examples-assembly-0.8.1-incubating.jar \
- --class org.apache.spark.examples.SparkTC \
- --args yarn-standalone \
- --num-workers 3 \
- --master-memory 2g \
- --worker-memory 2g \
- --worker-cores 1
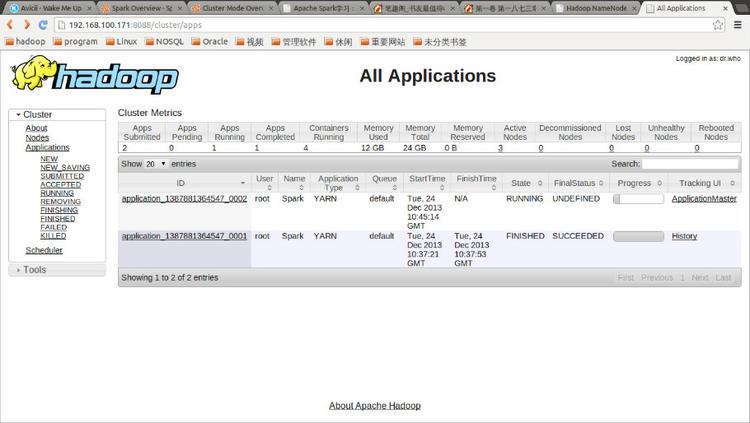
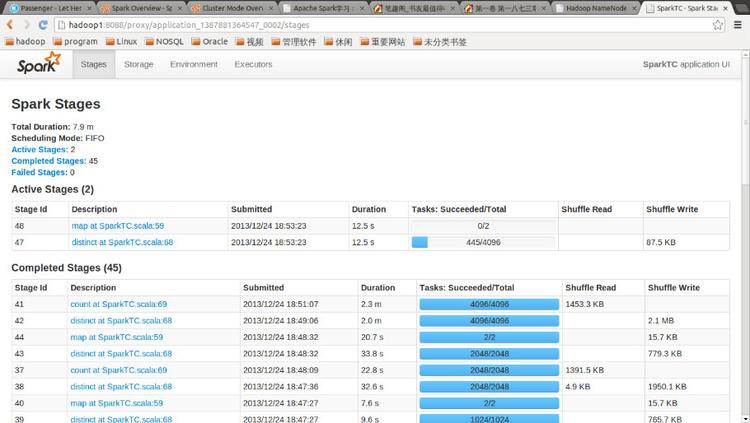
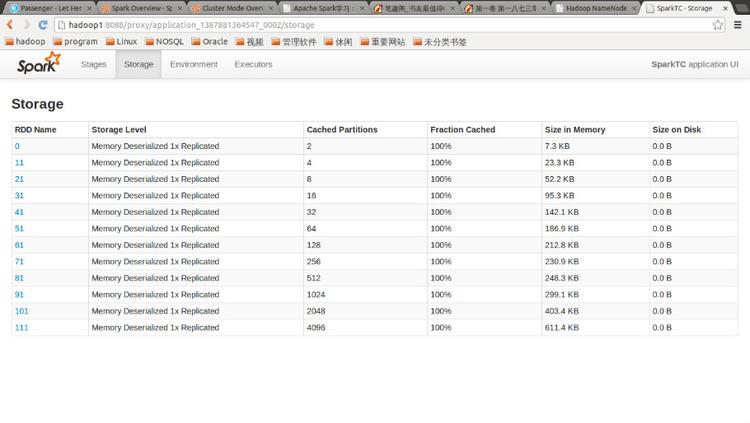
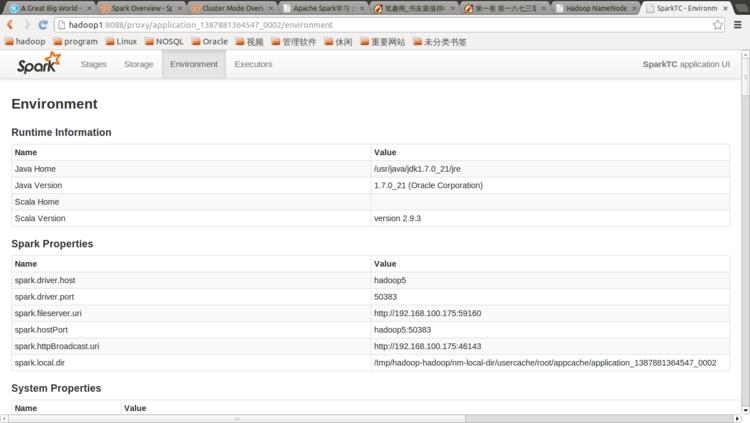
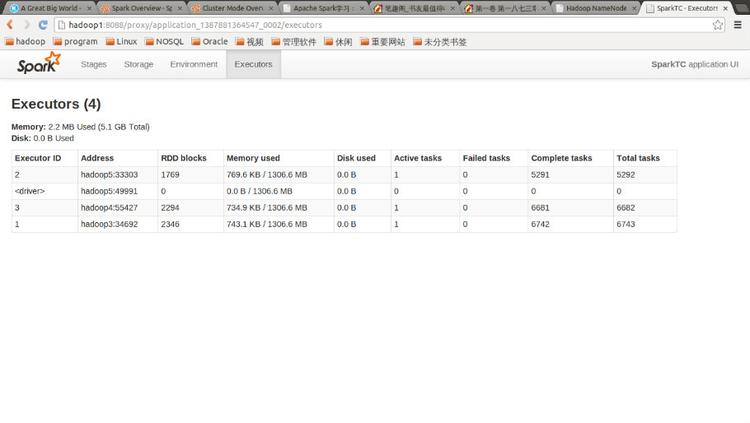
点击Tracking UI中的相应链接可以查看Spark的运行信息:



相关推荐
Spark on Yarn模式部署.docx
1. 解压Spark安装包 2. 配置Hadoop生态组件相关环境变量 2. 在 master 节点上,关闭HDFS的安全模式: 3. 在 master 节点上
描述了spark1.2.1在standalone集群模式和on yarn集群模式下的部署与运行方式。
资源是Spark 在yarn模式上的部署的spark安装包(spark-2.4.7-bin-hadoop2.7.tgz),以及安装部署的文档
个人总结的集群搭建运行事例环境文档。...有spark standalone模式 yarn模式 zookeeper的搭建 还有分布式文件系统hdfs hadoop搭建,内存式文件系统alluxio。开发环境的搭建idea for scala 的配置 ,和打包事例
1. spark 的有几种部署模式,每种模式特点? 2. Spark 为什么比 mapreduce 快? 3. 简单说一下 hadoop 和 spark 的 shuffle 相同和差异? 5. spark 的优化怎么做? 6. 数据本地性是在哪个环节确定的? 7. RDD 的弹性...
Spark Standalone 模式 Spark on Mesos Spark on YARN Spark on YARN 上运行 准备 Spark on YARN 配置 调试应用 Spark 属性 重要提示 在一个安全的集群中运行 用 Apache Oozie 来运行应用程序 Kerberos ...
YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内常用) Windows模式:为了方便在学习测试spark程序,Spark提供了可以在windows系统下启动本地集群的方式,这样,在不使用虚拟机或服务器的情况下,也...
详细介绍Spark2.3.0和Hadoop2.7.4集群在RedHat服务器部署,内涵hadoop 基于NFS 的HA高可用模式, yarn HA高可用, zookeeper安装,spark集群部署,NFS目录创建。对相关参数有详细介绍,以及提供了涉及到的Linux命令...
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。 1.Spark有几种部署模式,各个模式的特点 1.本地模式 ...3.Spark on yarn模式 分布式部署集群,资源和任务监控交给yarn管理 粗粒度
7.Spark on YARN 8.应用部署模式DeployMode 第二章、SparkCore 模块 1.RDD 概念及特性 2.RDD 创建 3.RDD 函数及使用 4.RDD 持久化 5.案例:SogouQ日志分析 6.RDD Checkpoint 7.外部数据源(HBase和MySQL) 8.广播...
大数据 大数据学习路线 大数据技术栈思维导图 大数据常用软件安装指南 一、Hadoop 分布式文件存储系统 —— ...Spark 运行模式与作业提交 Spark 累加器与广播变量 基于 Zookeeper 搭建 Spark 高可用集群 Spark SQL :
文章目录Spark下载和安装Spark的部署模式spark on yarnIDEA编写spark程序下载Scala安装Scala插件建立Maven工程编写wordcount程序打成jar包验证JAR包 Spark下载和安装 可以去Spark官网下载对应的spark版本。此处我...
将Spark应⽤迁移到K8s环境中 Spark Operator是Google基于Operator模式开发的⼀款的⼯具, ⽤于通过声明式的⽅式向K8s集群提交Spark作业,并且负责管理Spark 任务在K8s中的整个⽣命周期,其⼯作模式如下 我们可通过...
社区检测-火花-AWS 一个用Python3编写的Spark应用程序,用于通过双向标签传播算法找出... 步骤类型: Spark application (配置) 名称: labelp 部署方式: cluster 提交火花的选项: -- master yarn --driver-memory
YARN实现⼀个集群多个框架,例如⼀千台机器,同时部署了三个框架(MapReduce、Storm、Impala),会产⽣打架,有三个管家去底 层强CPU资源。如果三个产品只接受⼀个管家,就不会打架。出现了YARN资源调度和管理框架...
(我正在维护该项目,并添加有关Hadoop分布式模式,在云上部署Hadoop,Spark高性能,Spark流应用程序演示,Spark分布式集群等的更多演示。请给我一些支持。) 架构师大数据应用 数据输入:Apache Sqoop,Apache ...
6)Stream procressing(流式计算) Storm(实时数据处理分析) Kafka(分布式发布订阅消息系统) 拖放可视化设计,开发,部署和管理流式数据分析应⽤程序 进⾏事件关联,上下⽂衔接,复杂模式匹配,分析聚合以及创建警报/...
先后负责阿里YARN、spark及自主研发内存计算引擎 目前为广大公共云用户提供专业的云Hadoop服务及 云HBase服务. 阿里大数据三大组件 • 云 最佳实践 • 云 部署模式 • 云 真实案例 • 云 内核特性 • 云 未来